Real-world experiments
RC-NF as a plug-and-play monitor for VLA policies (e.g., π0), providing OOD signals for rollback or replanning with latency under 100 ms.
CVPR 2026
*Corresponding author
RC-NF as a plug-and-play monitor for VLA policies (e.g., π0), providing OOD signals for rollback or replanning with latency under 100 ms.
Evaluation on gripper open, slippage, and spatial misalignment anomalies.
Recent advances in Vision-Language-Action (VLA) models have enabled robots to execute increasingly complex tasks. However, VLA models trained through imitation learning struggle to operate reliably in dynamic environments and often fail under Out-of-Distribution (OOD) conditions.
To address this issue, we propose Robot-Conditioned Normalizing Flow (RC-NF), a real-time monitoring model for robotic anomaly detection and intervention that ensures the robot’s state and the object’s motion trajectory align with the task. RC-NF decouples the processing of task-aware robot and object states within the normalizing flow. It requires only positive samples for unsupervised training and calculates accurate robotic anomaly scores during inference through the probability density function.
We further present LIBERO-Anomaly-10, a benchmark comprising three categories of robotic anomalies for simulation evaluation. RC-NF achieves state-of-the-art performance across all anomaly types compared to previous methods in monitoring robotic tasks. Real-world experiments demonstrate that RC-NF operates as a plug-and-play module for VLA models (e.g., π0), providing a real-time OOD signal that enables state-level rollback or task-level replanning when necessary, with a response latency under 100 ms. These results have demonstrated that our RC-NF noticeably enhances the robustness and adaptability of VLA-based robotic systems in dynamic environments.
Expand each section for the full paper text (generated from the same LaTeX section sources as the PDF; figures and tables adapted for the web; math rendered with MathJax).
With the development of Vision-Language Models (VLM), Vision-Language-Action (VLA) models [5, 19, 20, 23, 52] are capable of performing an increasing variety of manipulation tasks from natural-language prompts. These VLA models are typically trained through imitation learning on expert demonstration data, and map high-level task prompts to low-level control actions. However, despite their impressive performance, VLA models often struggle when deployed in dynamic real-world environments, where Out-of-Distribution (OOD) scenarios occur frequently and can significantly degrade performance. As a result, VLA models require an accurate runtime monitoring system to determine whether the robot's execution remains consistent with the intended task in OOD situations.
Previous works on runtime monitoring typically formulate failure detection as a robotic state classification problem [3, 26, 38, 42, 43], requiring exhaustive enumeration of abnormal conditions or manually defined preconditions. However, this approach struggles to handle the combinatorial variability of real-world manipulation. Recent approaches have introduced high-level Vision-Language Models (VLMs), such as in dual-system architectures [6, 9, 12, 17, 28, 39, 51] and Sentinel [1], but these models require multi-step reasoning, resulting in multi-second latency, hindering timely intervention.
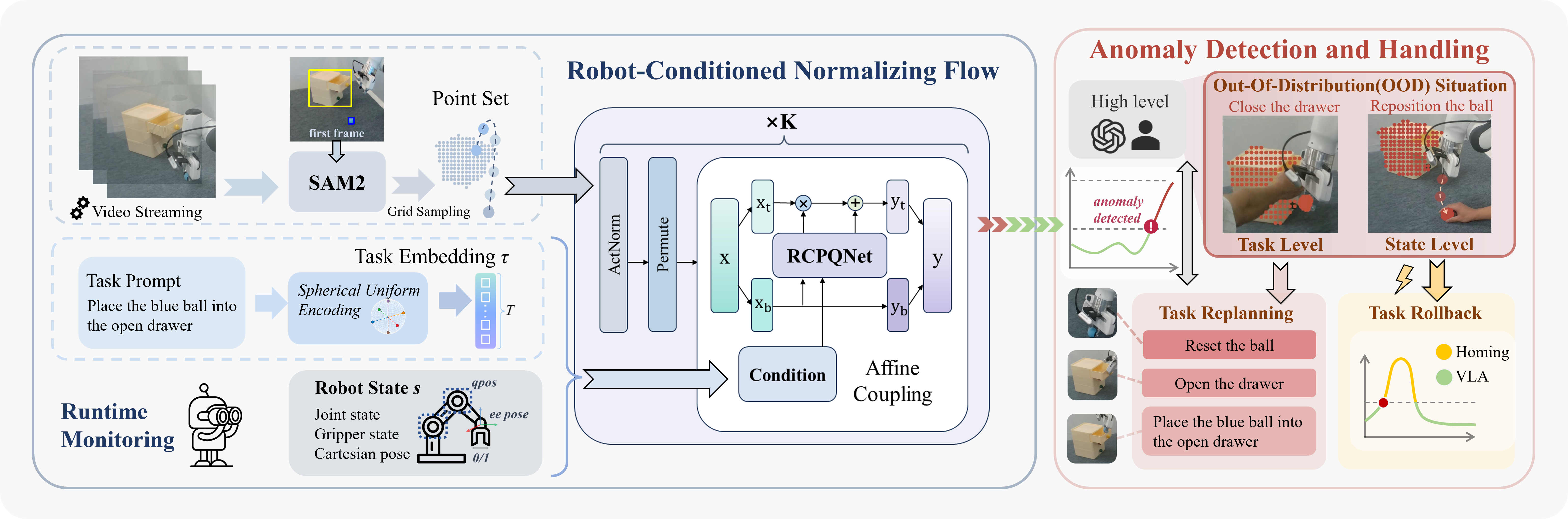
To address these limitations, we propose Robot-Conditioned Normalizing Flow (RC-NF), a real-time anomaly detection model that monitors whether the joint distribution of robot states and task-relevant object trajectories is consistent with normal task execution. Specifically, RC-NF is trained solely on successful demonstrations and models robot–object motion through a conditional normalizing flow. At runtime, it computes an anomaly score based on the probability density. If the score exceeds the threshold, behavioral drift is immediately detected. Key to RC-NF is a novel affine coupling layer, the Robot-Conditioned Point Query Network (RCPQNet), which fuses robot states, task embeddings, and object-centric point-set representations from SAM2 [32] segmentations. In particular, RCPQNet is designed to decouple robot state and object features while preserving their interactive features, providing a structured and expressive representation for manipulation tasks.
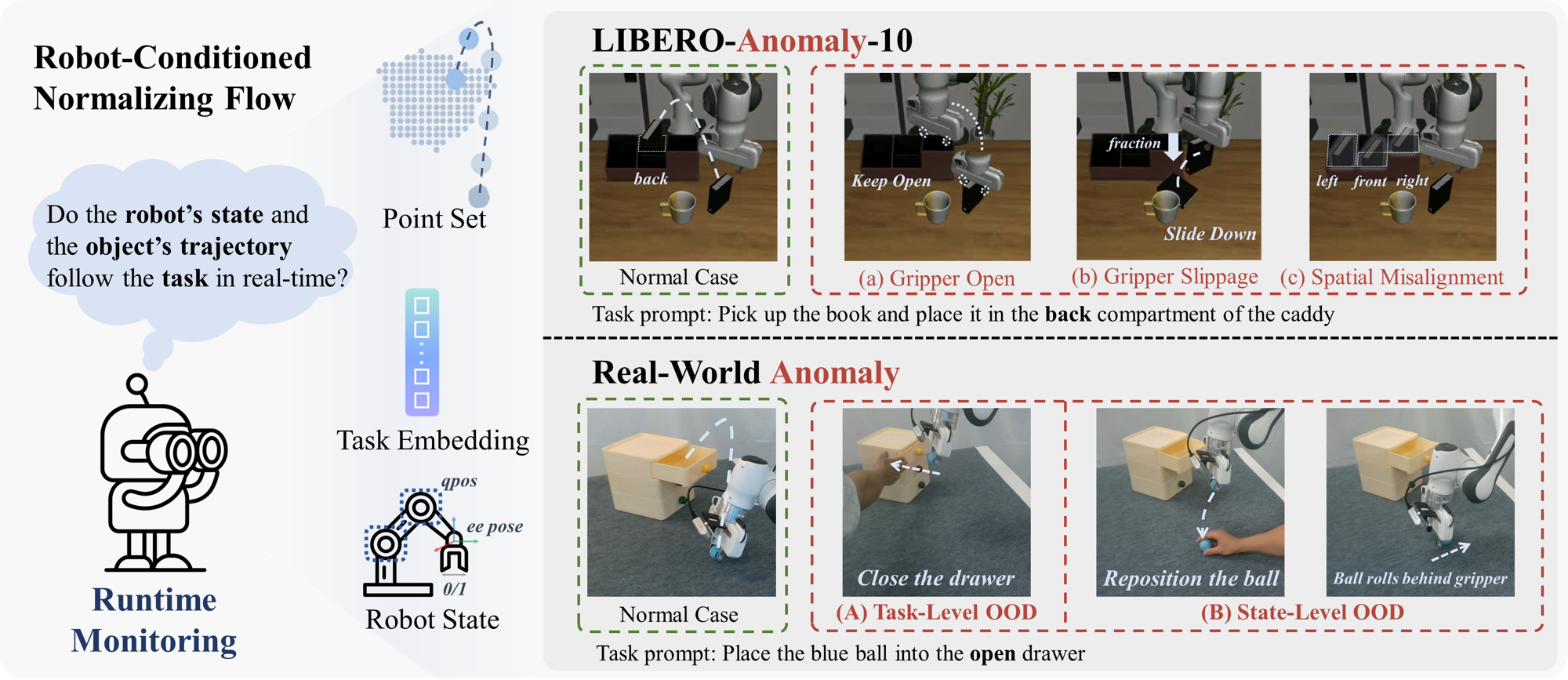
To evaluate our method, we introduce LIBERO-Anomaly-10, a benchmark for robotic anomaly detection built upon LIBERO-10 [25]. Unlike prior datasets focused on generalized task failures [1, 34, 36, 47], LIBERO-Anomaly-10 contains three manipulation-specific anomaly types—Gripper Open, Gripper Slippage, and Spatial Misalignment—each designed to test a different axis of deviation from expert trajectories. Compared to current state-of-the-art robotic monitoring model [47] and VLMs [1, 4, 8, 29], our proposed RC-NF achieves state-of-the-art performance across all anomaly types, surpassing the best baseline by approximately 8% AUC and 10% AP respectively.
In real-world deployment, RC-NF can detect anomalies within 100 ms. Furthermore, we demonstrate that RC-NF can trigger corrections for both task-level and state-level OOD situations, thereby enhancing the adaptability and robustness of VLA models (e.g., $\pi_0$ [5]). Task-level OOD occurs when the current VLA input task prompt no longer supports the task, requiring task replanning. State-level OOD refers to situations where the relative motion trajectory between the robot and the object drifts outside the VLA training distribution [35]. Although the instruction is still valid, recovery can still be achieved by adjusting the trajectory according to the original task. At the task level, RC-NF serves as a trigger for the high-level module, bridging the low-level and high-level modules. At the state level, RC-NF can trigger the homing procedure to correct the trajectory, enabling real-time adjustments for VLA.
In summary, our main contributions are as follows.
Normalizing Flow (NF) establishes a bidirectional mapping between the complex distribution \(\mathcal{X}\) and a simple probability distribution \(\mathcal{Z}\) via a sequence of invertible transformations \(f\), enabling explicit probability density estimation:
Taking the Glow [21] model as an example, the entire network consists of \(K\) flow steps \(f\). Each flow step comprises three layers: an ActNorm layer, a permutation layer, and an affine coupling layer. The ActNorm layer applies learnable channel-wise scaling and bias initialized with the first data batch, achieving normalization while preserving invertibility. The permutation transformation employs an invertible \(1\times1\) convolution to reorder feature channels. This formulation allows NF models to compute tractable likelihoods and to model complex distributions while maintaining differentiability and invertibility. The affine coupling layer splits the input into two parts, \( x_0 \) and \( x_1 \), using \( x_0 \) to compute the scale \( \gamma \) and shift \( \beta \) via a neural network. The affine transformation \( x_1 \odot \gamma + \beta \) is then applied to \( x_1 \), leaving \( x_0 \) unchanged. This design ensures invertibility with a tractable Jacobian determinant.
Building on the foundation of Normalizing Flow, as shown in Fig. [fig:method], we propose the Robot-Conditioned Normalizing Flow (RC-NF), which augments Glow with robot- and task-aware conditioning. Specifically, we design a new affine coupling layer—the Robot-Conditioned Point Query Network (RCPQNet, detailed in Sec. [sec:RCPQNet])—that integrates the robot’s execution state $s$ and target object trajectory $x_{\text{target}}$ to model the conditional probability of successful task execution. This formulation allows RC-NF to detect whether the joint distribution $p_{\mathcal{T}}(x_{\text{target}}, s)$ deviates from the task $\mathcal{T}$ by applying a threshold-based criterion.
Specifically, RC-NF extends a standard NF by conditioning on \( c = (s, \tau) \), where \( s \) denotes the robot state and \( \tau \) is the task embedding. The task embedding \( \tau \) is derived by mapping the current task prompt to a surface vector of a \( T \)-dimensional hypersphere with radius \( \mathcal{R} \). \( T \) is the number of sliding-window steps. These surface vectors, optimized to approximate a uniform distribution on the hypersphere, ensure maximal separation between task embeddings in the latent space, providing an optimal geometric structure for subsequent density estimation. The robot state \( s \) includes the \( T \)-dimensional joint state, gripper state, and Cartesian pose. As illustrated in Fig. [fig:method], the video stream captured by the camera is processed by SAM2 [32] to obtain object segmentation masks. Grid sampling is then applied to these masks to extract the shape representation of the manipulated objects. Given this point set \( \mathcal{X} \), RC-NF maps it into a Gaussian latent distribution \( \mathcal{Z} \sim \mathcal{N}(\mu_{\text{task}}, I) \), where the mean \( \mu_{\text{task}} \) is obtained by broadcasting the task embedding \( \tau \) to match the dimensionality of \( \mathcal{Z} \).
The conditional invertible mapping of RC-NF defines:
where \( x \in \mathcal{X} \), \( z \in \mathcal{Z} \), and \( f_c \) is a composition of \( K \) conditional transformations, with intermediate representations \( y_i \), and final output \( z = y_K \):
Based on the change-of-variables principle, where the Jacobian determinant accounts for the local volume change induced by the transformation, we can compute the conditional likelihood of $x$ given $c$ as follows:
Taking the logarithm of Eq. (NF0) and expanding over $K$ steps:
During training, we maximize the log-likelihood in Eq. (NF2). For a Gaussian prior over the latent variable $z$, the log-probability term can be expressed as:
The resulting log-probability reflects the likelihood that the current robot-object configuration belongs to the nominal task distribution, with the negative value representing the anomaly score. Each conditional transformation $f_{i, c}$ in RC-NF employs an affine coupling layer parameterized by the Robot-Conditioned Point Query Network (RCPQNet), which fuses task embeddings and robot states to generate context-dependent transformation parameters.
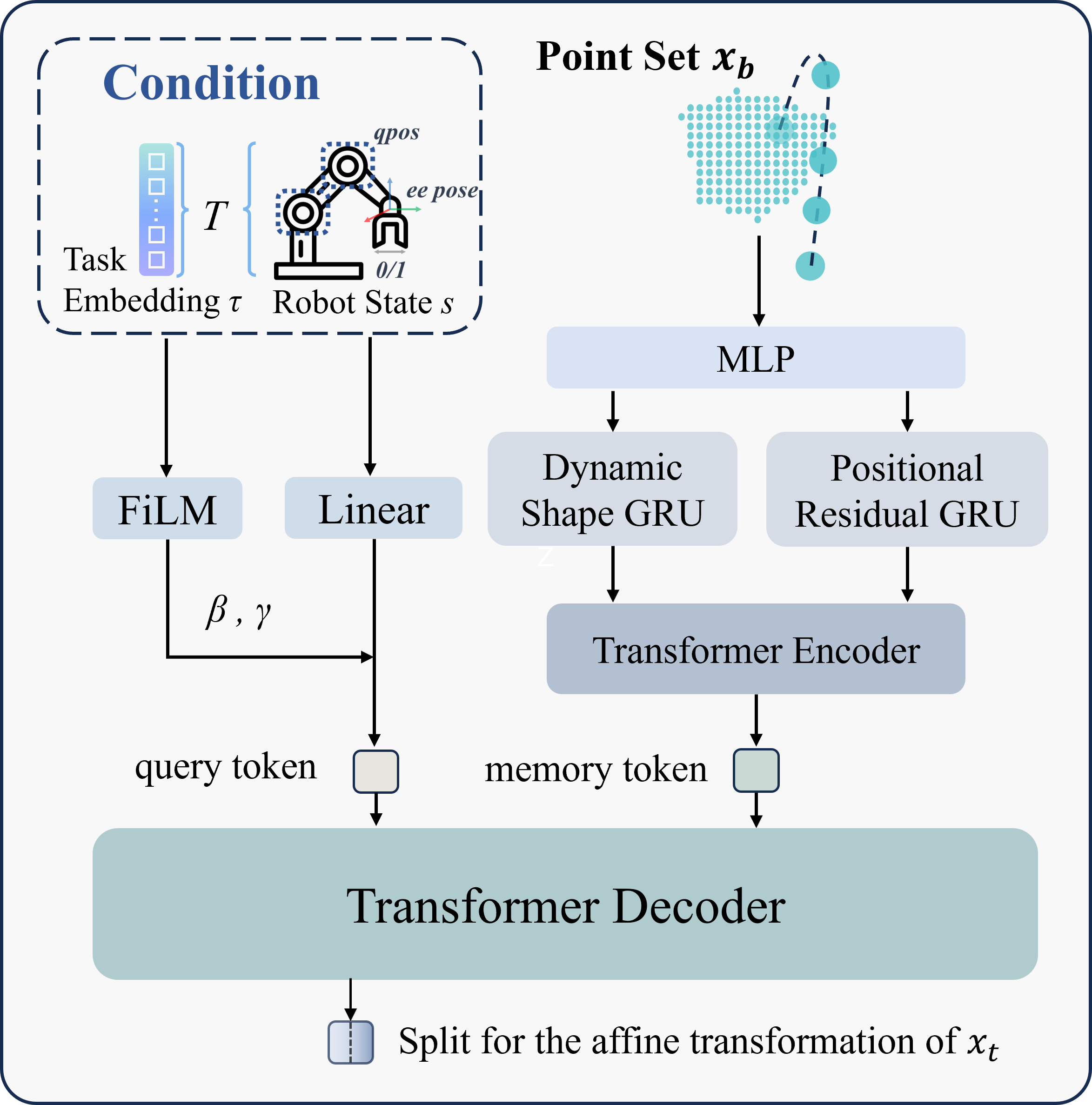
As shown in Fig. [fig:method], we denote the point set generated by SAM2 as \( x \in \mathbb{R}^{B \times T \times N \times 2} \), where \( B \) represents the batch size, \( T \) is the number of sliding-window steps, \( N \) denotes the number of sampled points per object mask, and the last dimension corresponds to the 2D coordinates of each point. The point set after the ActNorm and Permute layers of the first flow step is also denoted as \( x \), which is used as an example to illustrate the processing flow of the RCPQNet. The point set \( x \) is split into two halves along the temporal dimension: \( x_b = x[:T/2] \) and \( x_t = x[T/2:] \).
The scaling factor \( \gamma \) and shift \( \beta \) are obtained by applying \( \text{RCPQNet}(x_b, c) \), where \( c = (s, \tau) \), as detailed in Sec. [sec:RC-NF]:
Based on the above definition, the output of the flow step y, can be expressed as:
As illustrated in Fig. [fig:RCPQ], RCPQNet utilizes Task-aware Robot-Conditioned Queries to generate the query token and Dual-Branch Point Feature Encoding to create the memory token. They are then used in cross-attention within the transformer. Hence, the model learns context-aware affine parameters that adjust the flow’s transformation based on the robot’s current state and the performing task.
Task-aware Robot-Conditioned Query. The robot state is first projected into a latent space through a linear layer and then modulated by the task embedding \(\tau\) using FiLM[31] to produce task-specific query features. These query tokens encode both the robot’s state context and the high-level goal specified by the task prompt, serving as dynamic keys for retrieving relevant temporal and spatial cues from subsequent feature memories.
Dual-Branch Point Feature Encoding. To capture complementary spatial-temporal representations, RCPQNet employs Dual-Branch Point Feature Encoding. The Dynamic Shape branch performs centering and normalization on each frame to eliminate translation and scale effects during the extraction of shape features. The Positional Residual branch focuses on compensating for the information lost during shape normalization of the raw point set. Subsequently, the features are passed through an MLP to increase their dimensionality and then average-pooled to obtain frame-level representations. These representations are sequentially modeled by their respective GRUs to capture temporal dependencies. Finally, they are encoded by a Transformer encoder to produce the memory vectors.
Anomaly Detection. During deployment, RC-NF functions as a plug-and-play and real-time monitoring module that can be seamlessly integrated into existing VLA control loops without architectural modification (see Fig. [fig:method]). Operating in parallel with the policy network, RC-NF continuously observes both the visual stream and robot-state feedback, estimating the likelihood of the current execution trajectory under the learned nominal task distribution. At each time step, the negative log-likelihood of the observed configuration is used as an anomaly score, where higher values indicate greater deviation from expected task execution.
When the anomaly score exceeds an upper threshold, it indicates both an anomaly and an OOD condition. During RC-NF training, debiasing is applied to ensure the temporal smoothness of anomaly scores in each demonstration. Therefore, we adopt a static threshold that does not vary over time. For each task \( \mathcal{T} \), the upper threshold is estimated using calibration datasets \( S_1 \) and \( S_2 \) derived from successful expert demonstrations[37, 47]:
where \( \mu_\mathcal{T} \) is the mean anomaly score from \( S_1 \), and \( D_T = \{D_1, \dots, D_{n_2}\} \) denotes the score deviations from \( \mu_\mathcal{T} \) values in \( S_2 \). \( Q_{1-\alpha}(D_\mathcal{T}) \) is the \( (1-\alpha) \)-quantile.
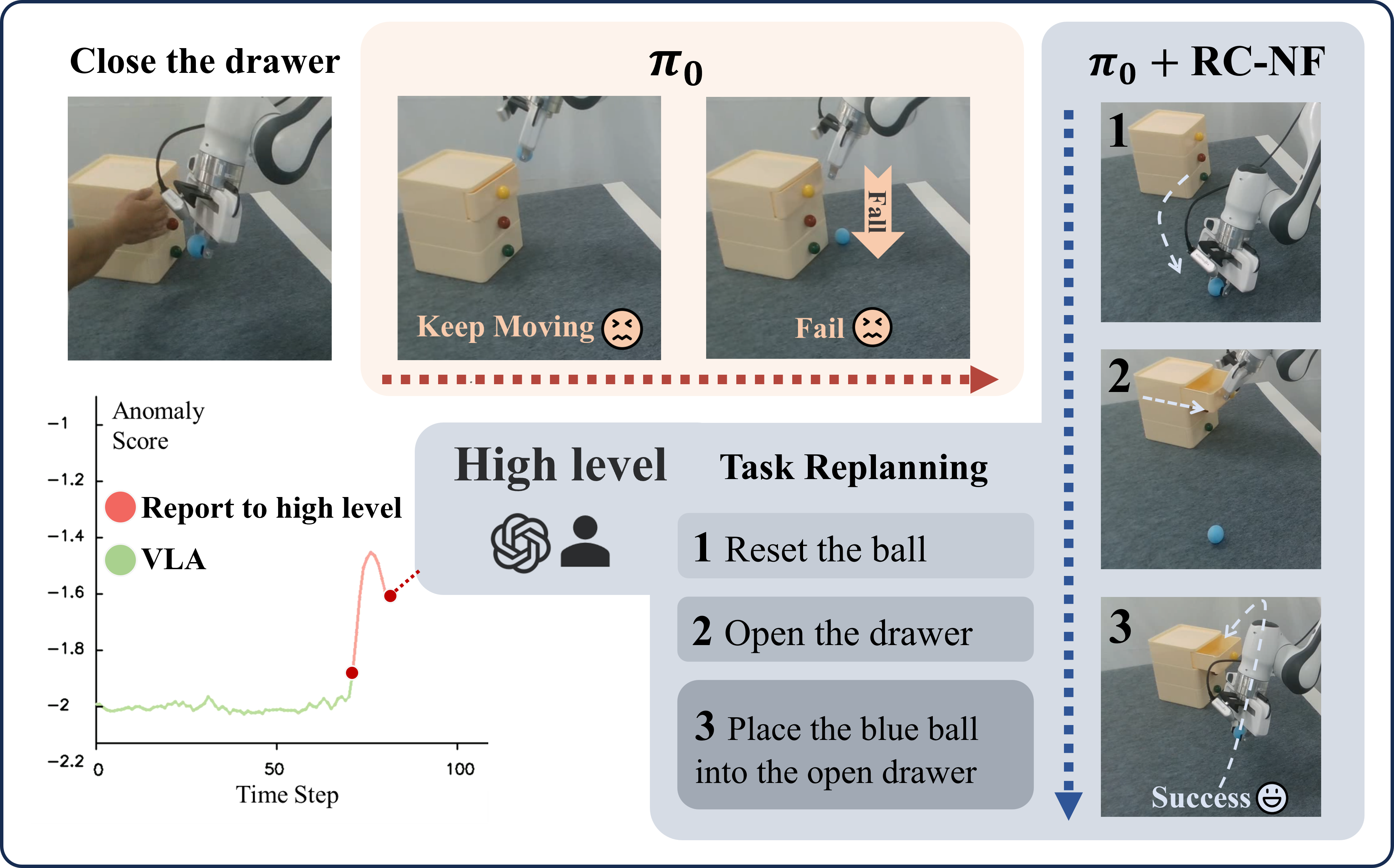
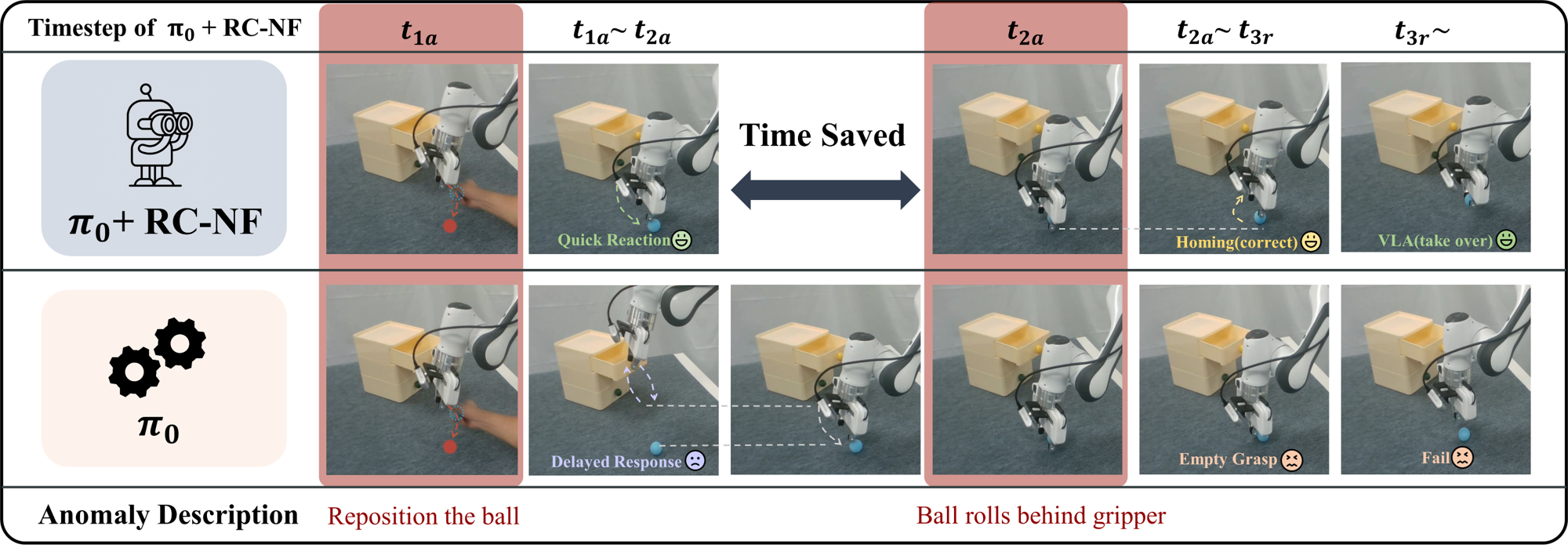
Anomaly Handling. Once an anomaly is detected, a high-level system determines whether it corresponds to a state-level or task-level OOD case. In practice, the system first performs a lightweight state-level recovery and escalates to task-level replanning if required. On one hand, task-level OOD represents that the environment or context no longer matches the given instruction. For instance, the drawer becomes closed when the prompt specifies place the blue ball into the open drawer. In this case, RC-NF alerts the high-level controller (e.g, a human operator or LLM-based planner) to perform task replanning, producing an updated sequence of sub-tasks or object interactions consistent with the new environmental state. On the other hand, state-level OOD indicates that the task remains valid, but the robot’s physical configuration has drifted from the nominal distribution. For example, during the execution of the task place the blue ball into the open drawer, if the ball falls from the gripper onto the table (in this experiment, we manually reposition the ball from the gripper onto the table), RC-NF detects an increase in the anomaly score. Then a homing procedure, designed to return the robotic arm to its initial state, is activated for task rollback. It locally adjusts the trajectory or control parameters until the anomaly score falls below the threshold. Once the environment and robot state return to the familiar data distribution, execution control is seamlessly handed back to the VLA for normal operation.
| Method | Gripper Open | Gripper Slippage | Spatial Misalignment | Average | ||||
|---|---|---|---|---|---|---|---|---|
| AUC | AP | AUC | AP | AUC | AP | AUC | AP | |
| GPT-5 | 0.9137 | 0.9642 | 0.8941 | 0.8720 | 0.4904 | 0.4015 | 0.8500 | 0.8507 |
| Gemini 2.5 Pro | 0.8644 | 0.9333 | 0.8633 | 0.8505 | 0.5167 | 0.4271 | 0.8186 | 0.8313 |
| Claude 4.5 | 0.8754 | 0.9401 | 0.8551 | 0.8285 | 0.5292 | 0.4290 | 0.8214 | 0.8249 |
| FailDetect | 0.7883 | 0.9032 | 0.6665 | 0.6932 | 0.6557 | 0.5820 | 0.7181 | 0.7700 |
| RC-NF (Ours) | 0.9312 | 0.9781 | 0.9195 | 0.9180 | 0.9676 | 0.9585 | 0.9309 | 0.9494 |
We primarily conduct quantitative analysis of RC-NF's anomaly detection capability through simulation experiments, and demonstrate the significance of the monitoring mechanism through real-world robotic tasks.
Datasets. We train RC-NF on the original LIBERO-10 dataset, which efficiently encompasses all the scenarios present in the LIBERO dataset[25], with 50 demonstrations per task. We evaluate it on our proposed LIBERO-Anomaly-10 benchmark. It introduces three distinct anomaly types, illustrated in Fig. [fig:main]: (1) Gripper Open: the gripper remains open at $t_{\text{anomaly}}$, when it should grasp the object, leaving the object untouched and unperturbed. This case tests a situation where the object position remains normal, but the robot state does not align with it. (2) Gripper Slippage: at $t_{\text{anomaly}}$, when the gripper is holding the object, the gripper friction is set to zero, causing the object to slip and produce abnormal trajectory fluctuations. (3) Spatial Misalignment: the robot moves toward the wrong compartment (left, front or right) instead of the intended back at $t_{\text{anomaly}}$, testing semantic–spatial misalignment between the task prompt and motion direction.
During annotation, the period before $t_{\text{anomaly}}$ is labeled as normal and after $t_{\text{anomaly}}$ as abnormal. Gripper Open and Gripper Slippage are generated for all ten tasks in LIBERO-10, whereas Spatial Misalignment corresponds to tasks involving three different incorrect compartment placements (front, left, and right), rather than the demo task Pick up the book and place it in the back compartment of the caddy.
Baselines and Evaluation Metrics. We compare RC-NF against two categories of methods. The first category is VLM-based monitoring method, represented by Sentinel [1], where we employ the most advanced VLMs, GPT-5 [29], Gemini 2.5 Pro [8], and Claude 4.5 [4]. They are evaluated under conditions involving parallel invocation and a sampling frequency of 1 Hz. The second category is also flow-based, represented by FailDetect [47], a flow-matching model that jointly encodes image and robot-state features for unsupervised failure detection.
We evaluate the model using Area Under the ROC Curve (AUC) and Average Precision (AP). AUC assesses the model's overall discriminatory ability, while AP focuses on precision-recall performance, particularly for imbalanced tasks like anomaly detection. These threshold-independent metrics offer a comprehensive evaluation of both discriminatory power and precision-recall trade-offs.
Real-World Setup. Experiments are conducted on a Franka Research 3 robotic arm equipped with both a wrist-mounted and a third-person camera, both of which are Intel RealSense D435 depth cameras. VLA model $\pi_0$ [5] is adopted as the imitation policy baseline. The training demonstrations for both VLA and RC-NF are consistent. VLA uses both camera views during training, while RC-NF uses only the third-person camera for monitoring. The threshold parameters of real-world experiments in Eq. (threshold) are set with \( \alpha = 0.05 \), following the design of FailDetect [47].
Implementation Details. As shown in Fig. [fig:method], before SAM2 processes the video stream, a bounding box prompt is required for the first frame. In the simulation environment, computer graphics techniques are used to ensure the reproducibility of the point set. In the real-world setup, the bounding box is obtained using the Gemini 2.5 Pro.
The parameters of FailDetect [47] follow its open-source code exactly. The prompts for the VLMs are derived from Sentinel [1], originally designed for task progress assessment, and are used in this paper as anomaly scores with the following anchors: 0–3 (normal), 4–6 (slightly abnormal), and 7–10 (strongly abnormal). For RC-NF, the number of flow steps is \( K = 12 \) and the model is trained for 100 epochs with debiasing applied for data balancing. More details can be found in the Supplementary Materials.
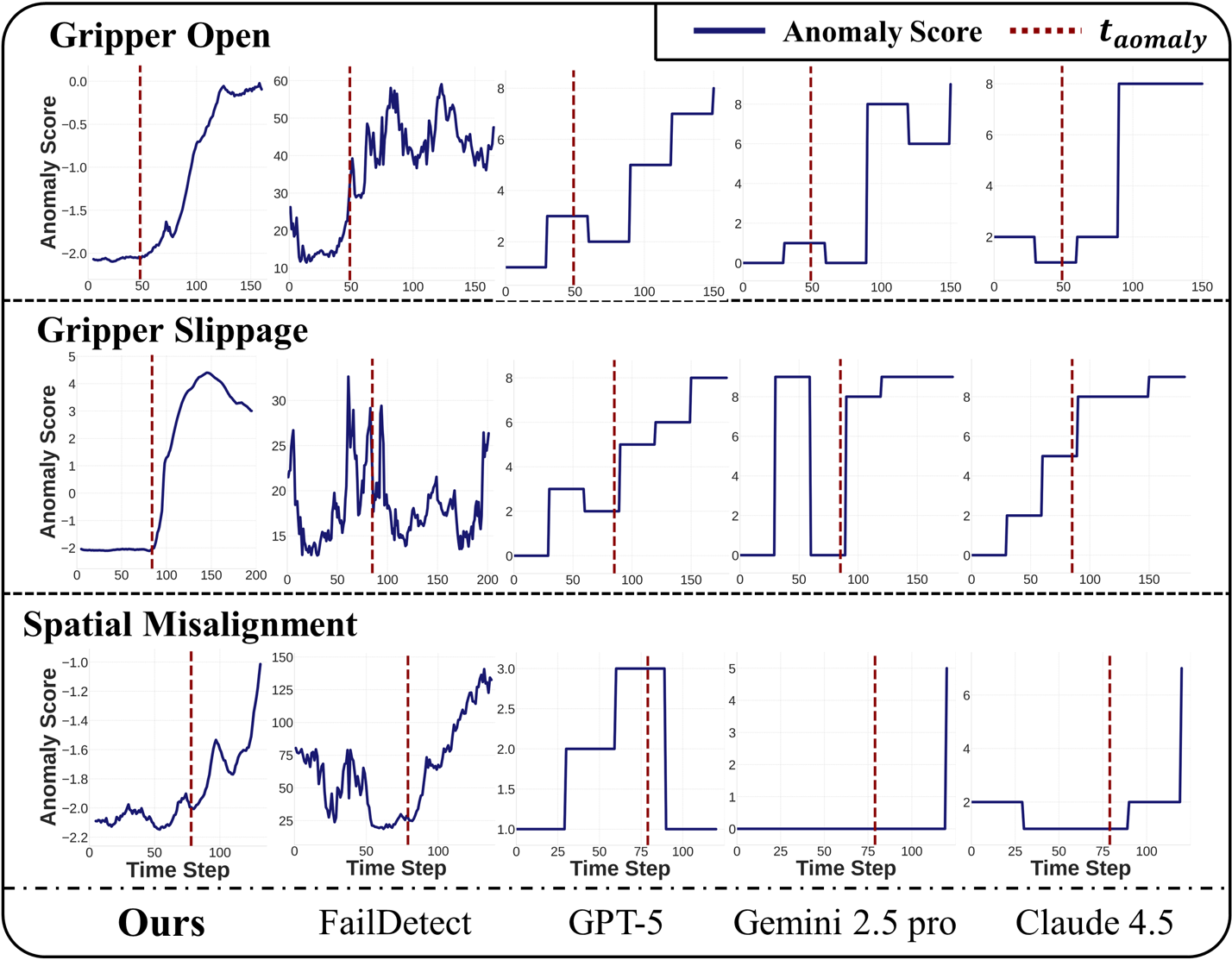
Table [tab:sim1] presents a comparison of anomaly detection performance on the LIBERO-Anomaly-10 benchmark. Across all anomaly types, RC-NF consistently outperforms baselines across all metrics, surpassing the best prior method by about 8% in AUC and 10.0% in AP on average.
VLMs achieve moderate success in Gripper Open and Gripper Slippage but degrade to near-random performance (AUC $\approx$ 0.5, AP $\approx$ 0.4) on Spatial Misalignment, highlighting their difficulty in aligning visual semantics with spatial reasoning. In contrast, RC-NF can precisely compute the degree of deviation from the normal trajectory for the task in real-time, replacing semantic understanding with the spatial trajectories of the object and robot arm.
Compared to FailDetect, RC-NF offers significant advantages in feature selection and feature processing for robotic anomaly monitoring. In terms of feature selection, RC-NF operates on a refined point-set representation derived from segmentation masks, which offers greater robustness to noise than raw image features used in FailDetect. Regarding feature processing, RC-NF treats the robot state features as query tokens and the object point features as memory tokens, enabling an efficient and decoupled design that encourages multimodal information interaction while avoiding feature interference. By contrast, FailDetect concatenates robot and image features as flow-matching inputs, leading to entangled representations and feature imbalance.
Fig. [fig:exp_sim1] visualizes the anomaly detection curves for the task Pick up the book and place it in the back compartment of the caddy. RC-NF maintains a stable score of -2 before \( t_{\text{anomaly}} \) for each task, indicating normal behavior. Once an anomaly occurs after \( t_{\text{anomaly}} \), as indicated by the red dashed line, it quickly reacts by increasing the anomaly score. Compared to VLM-based monitoring methods, RC-NF can calculate the anomaly score in real-time without the need for prolonged inference or reasoning. In contrast to FailDetect, RC-NF produces scores that are superior in terms of smoothness, stability, and accuracy, which can be attributed to its structured feature decoupling and robot-conditioned flow formulation.
| Row | Method | Gripper Open | Gripper Slippage | Spatial Misalignment | Average | ||||
|---|---|---|---|---|---|---|---|---|---|
| AUC | AP | AUC | AP | AUC | AP | AUC | AP | ||
| 1 | RC-NF (Ours) | 0.9312 | 0.9781 | 0.9195 | 0.9180 | 0.9676 | 0.9585 | 0.9309 | 0.9494 |
| 2 | w/o Task Embedding | 0.8769 | 0.9603 | 0.8668 | 0.8680 | 0.8139 | 0.8118 | 0.8643 | 0.9008 |
| 3 | w/o Robot State | 0.6327 | 0.8621 | 0.7443 | 0.8116 | 0.8929 | 0.8617 | 0.7152 | 0.8401 |
| 4 | w/o Pos. Residual branch | 0.9045 | 0.9712 | 0.8971 | 0.9085 | 0.8543 | 0.8072 | 0.8947 | 0.9225 |
| 5 | w/o Dyn. Shape branch | 0.7666 | 0.9234 | 0.7763 | 0.8108 | 0.1022 | 0.2755 | 0.6841 | 0.7899 |
To investigate the effectiveness of the proposed Robot-Conditioned Point Query Network (RCPQNet), as shown in Table [tab:sim2], we perform ablations on the two principal components introduced in Sec. [sec:RCPQNet].
Effect of Task-Aware Robot-Conditioned Query. To assess the role of task modulation and robot awareness, we remove either the task embedding or the robot-state features. When the task embedding is removed (Row 2), the point set \( \mathcal{X} \) is projected into the latent space \( \mathcal{Z} \sim \mathcal{N}(0, I) \). As a result, model can only detect dataset-level OOD samples but fails to distinguish task-specific anomalies. Performance on Spatial Misalignment drops nearly threefold compared to the counterparts, confirming that task embeddings are crucial for encoding spatial intent and disambiguating similar object trajectories under different instructions. In addition, removing robot-state features (Row 3) eliminates contextual grounding of object motion. For the Gripper Open anomaly, since the gripper remaining open does not directly displace the object, the anomaly manifests in the relative motion between the robot and the object, leading to the greatest drop in AUC. In contrast, for the Spatial Misalignment anomaly, the anomaly can be detected through the object's positional deviation, leading to the least decline. These results highlight that robot-conditioned query enables RC-NF to reason jointly about robot–object motion, resulting in more precise anomaly localization.
Effect of Dual-Branch Point Feature Encoding. We further examine the contribution of the two encoding branches within RCPQNet: the Positional Residual branch and the Dynamic Shape branch. Removing the positional branch (Row 4) results in a moderate drop, with an average AUC of approximately 0.89, suggesting that absolute spatial information complements dynamic-shape cues by preserving average shifts within robot-object motion features. The Dynamic Shape branch treats the point sets of all objects as a unified whole, representing the relative movements between target objects as shape variations of the entire set. Removing this branch (Row 5) leads to the greatest degradation (AUC $\approx$ 0.68 on average), underscoring its importance in Dual-Branch Point Feature Encoding. The sharp decline observed under Spatial Misalignment further indicates that temporal shape evolution provides stronger evidence of abnormality than inter-frame average positional shifts.
We further conduct real-world evaluations to demonstrate how RC-NF enhances the adaptability and robustness of Vision-Language-Action (VLA) policies. The study focuses on the representative scenario placing the blue ball into the open drawer and associated derivative tasks using the \( \pi_0 \) model as the baseline. In real-world deployment, RC-NF can detect anomalies within 100 ms on a consumer-grade GPU such as Nvidia GeForce RTX 3090. Related videos can be found in the Supplementary Materials.
Task-Level Anomaly Handling. As shown in Fig. [fig:exp_real0], during the execution of the task, if the drawer closes unexpectedly, \( \pi_0 \) policy continues execution and fails. With our RC-NF, the anomaly score computed from the visual stream and robot state increases sharply beyond the threshold defined in Eq. (threshold). \( \pi_0 \)+RC-NF manages to pause the motion and signals the high-level controller (human or LLM planner) to initiate task replanning, i.e., reset the ball and open the drawer first, then execute the task normally, leading to task success.
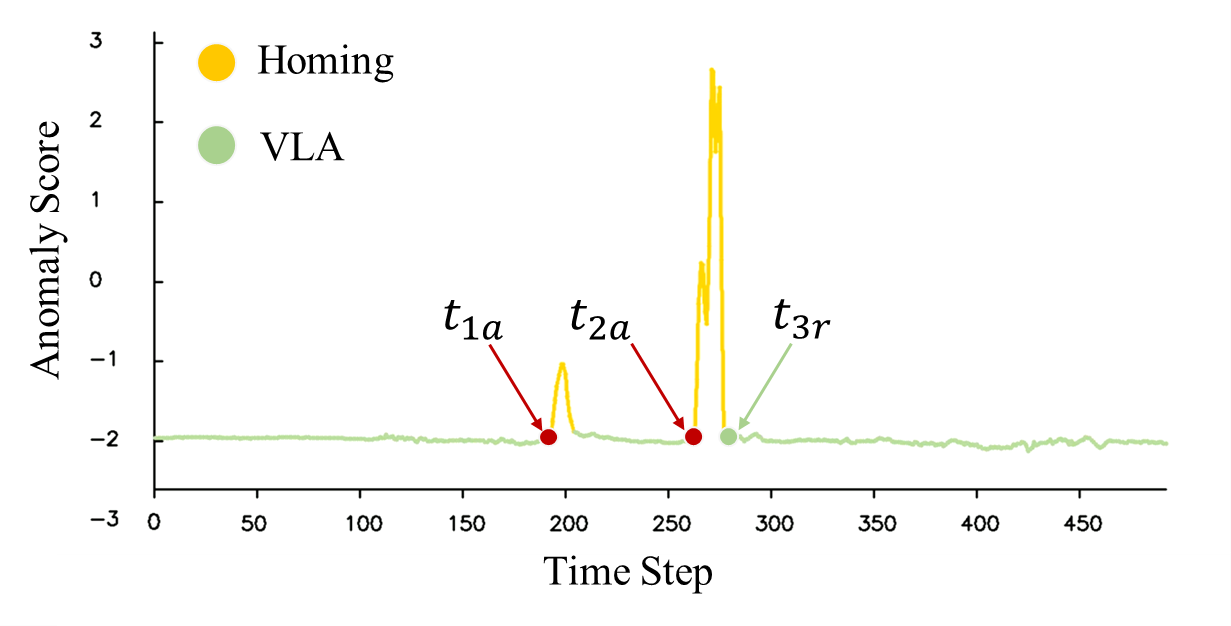
State-Level Anomaly Handling. As shown in Fig. [fig:exp_real1] and [fig:exp_real2], we next examine state-level disturbances that preserve task intent but perturb execution dynamics. At $t_{1a}$, when the ball returns to the table, RC-NF quickly signals an anomaly and activates the homing procedure to re-align the trajectory. Nevertheless, $\pi_0$ alone experiences a delay, which continues moving to the drawer with empty gripper. In addition, when the ball rolls behind the gripper at $t_{2a}$, RC-NF detects the anomaly immediately and adjusts the trajectory towards the new position of the ball. Once the anomaly score drops to normal at \( t_{3r} \), control is seamlessly returned to VLA for regular operation. Without RC-NF, $\pi_0$ continues to move incorrectly, causing the gripper to grasp air and lift.
The real-world evaluation demonstrates that RC-NF transfers effectively from simulation to physical settings. It provides low-latency feedback for both task-level and state-level OOD anomalies, enabling safe and adaptive execution without altering the underlying VLA architecture. The plug-and-play design allows direct integration with existing imitation-learning policies, enhancing robustness and situational awareness in unstructured environments.
We introduced the Robot-Conditioned Normalizing Flow model, designed to enhance the adaptability of VLA models in dynamic real-world environments. By utilizing Task-aware Robot-Conditioned Query and Dual-Branch Point Feature Encoding, RC-NF enables real-time robotic anomaly detection, improving the robot's ability to handle Out-of-distribution scenarios. Our quantitative experiments on the LIBERO-Anomaly-10 benchmark show that RC-NF outperforms existing methods for monitoring, achieving state-of-the-art AUC and AP scores. These results underscore RC-NF's effectiveness in monitoring robotic tasks, detecting deviations in task execution and object motion. RC-NF acts as a real-time monitor that produces a general-purpose OOD signal meaningful across different granularities. Real-world evaluations further confirm RC-NF’s effectiveness, highlighting its fast response (under 100 ms) and seamless integration with the VLA policy (e.g. \( \pi_0 \)).
This work was supported by the Science and Technology Commission of Shanghai Municipality (No. 24511103100) and the National Natural Science Foundation of China (NSFC) under Grant No. 62521004. It was also supported by the Ministry of Education (MOE), Singapore, under its Academic Research Fund (AcRF) Tier 2 (Proposal ID: T2EP20125-0048). Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the Ministry of Education, Singapore.
@article{zhou2026rc,
title={RC-NF: Robot-Conditioned Normalizing Flow for Real-Time Anomaly Detection in Robotic Manipulation},
author={Zhou, Shijie and Zhu, Bin and Yang, Jiarui and Zhao, Xiangyu and Chen, Jingjing and Jiang, Yu-Gang},
journal={arXiv preprint arXiv:2603.11106},
year={2026}
}